Introduction
A risk as LLMs grow more capable is that they learn unsafe knowledge during training. These dangerous capabilities could be exploited by bad actors. Today's safeguards focus on suppressing unsafe knowledge in post-training, often via refusal training. The unsafe knowledge remains in the model's weights.
Open-weight models, those that users can download and modify locally, offer unique benefits related to transparency, research, and the deconcentration of power. However, they are vulnerable to "tampering attacks" that can remove their safety training. For instance, it is straightforward to train open-weight models never to refuse unsafe requests. This is of increasing concern as open-weight models begin to rival the capabilities of the best closed-weight models.
We explore an intuitive yet understudied question: Can we prevent LLMs from learning unsafe technical capabilities (such as CBRN) by filtering out enough of the relevant pretraining data before we begin training a model? We train multiple 6.9B LLMs from scratch on an unfiltered dataset and on filtered versions where we filtered out biorisk knowledge. We observe three main results:
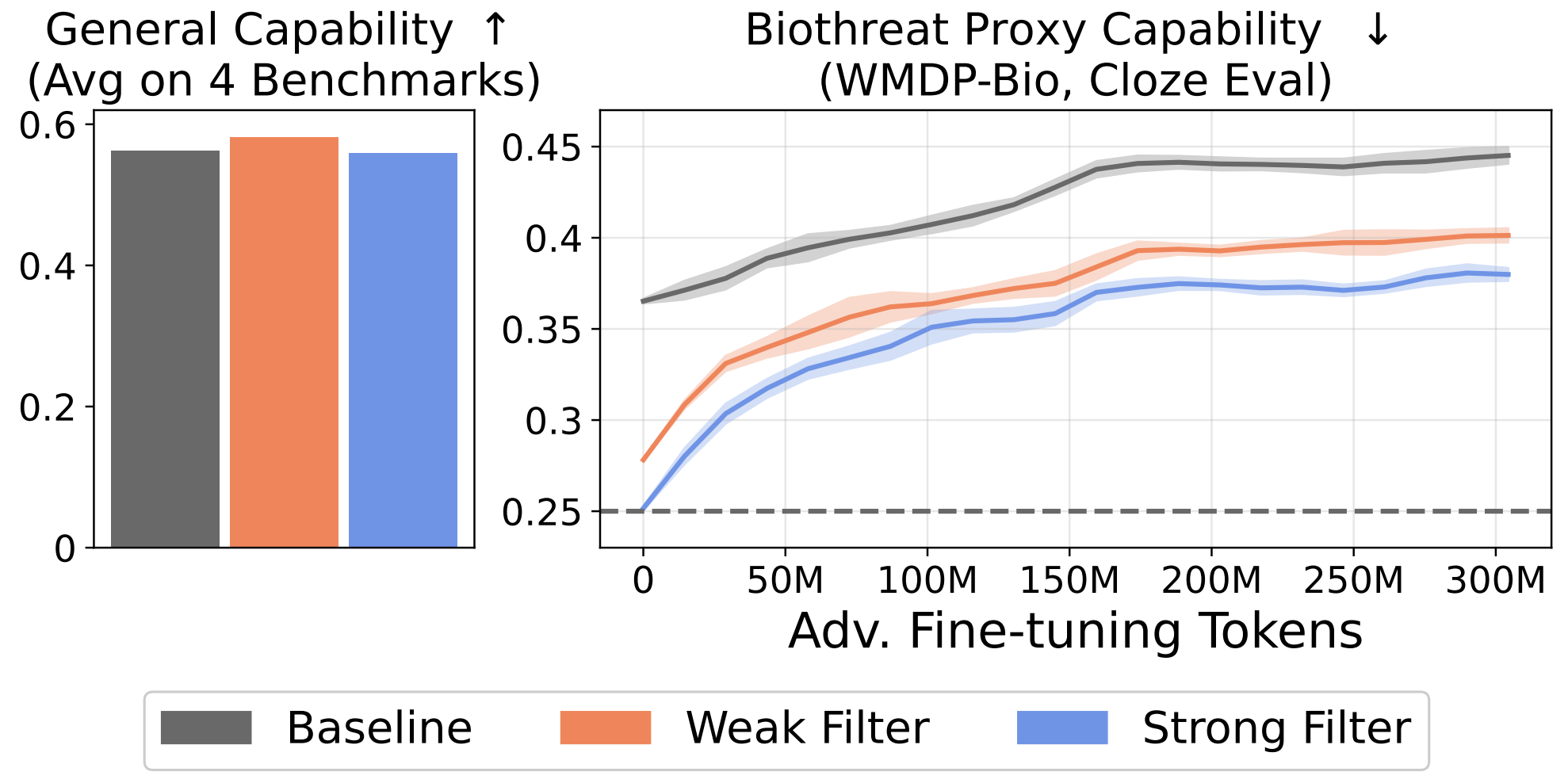
- Knowledge Prevention: The filtered models perform significantly worse on our biorisk knowledge evaluations, nearly at random chance. Crucially, filtering does not lead to notable regressions in general knowledge. These results suggest that data filtering may be a simple way to prevent models from learning dangerous capabilities without sacrificing utility.
- Tamper-Resistance: Open-weight models can be fine-tuned by downstream users on biorisk data. We study this attack by fine-tuning our models on 300M tokens of high-quality biorisk-related documents. We find that performance can improve, but that it is still well below the no-filtering baseline. Data filtering is significantly more tamper-resistant than current safeguards.
- Defense-in-Depth: We demonstrate that data filtering cannot prevent LLMs from leveraging harmful knowledge provided in-context, but that Circuit-Breaking-based techniques offer complementary defenses. However, we show that none of the defenses we test are resistant to staged attacks that combine fine-tuning and in-context retrieval.
Taken together, these results suggest that rigorous pretraining data filtering is a promising method for preventing acquisition of dangerous technical capabilities without obvious degradation in overall model utility. Our efficient data approach allowed us to perform filtering with less than a 1% increase in training compute (FLOPS). We release our models, optimizer states, and intermediate checkpoints to enable future research into domains including data-driven AI security, pretraining research, machine unlearning, and mechanistic interpretability. We are especially excited to see future work that addresses our limitations, such as studying the filtering of other types of knowledge and developing scaling trends. See our paper for more details, discussion, and sketches of future work.
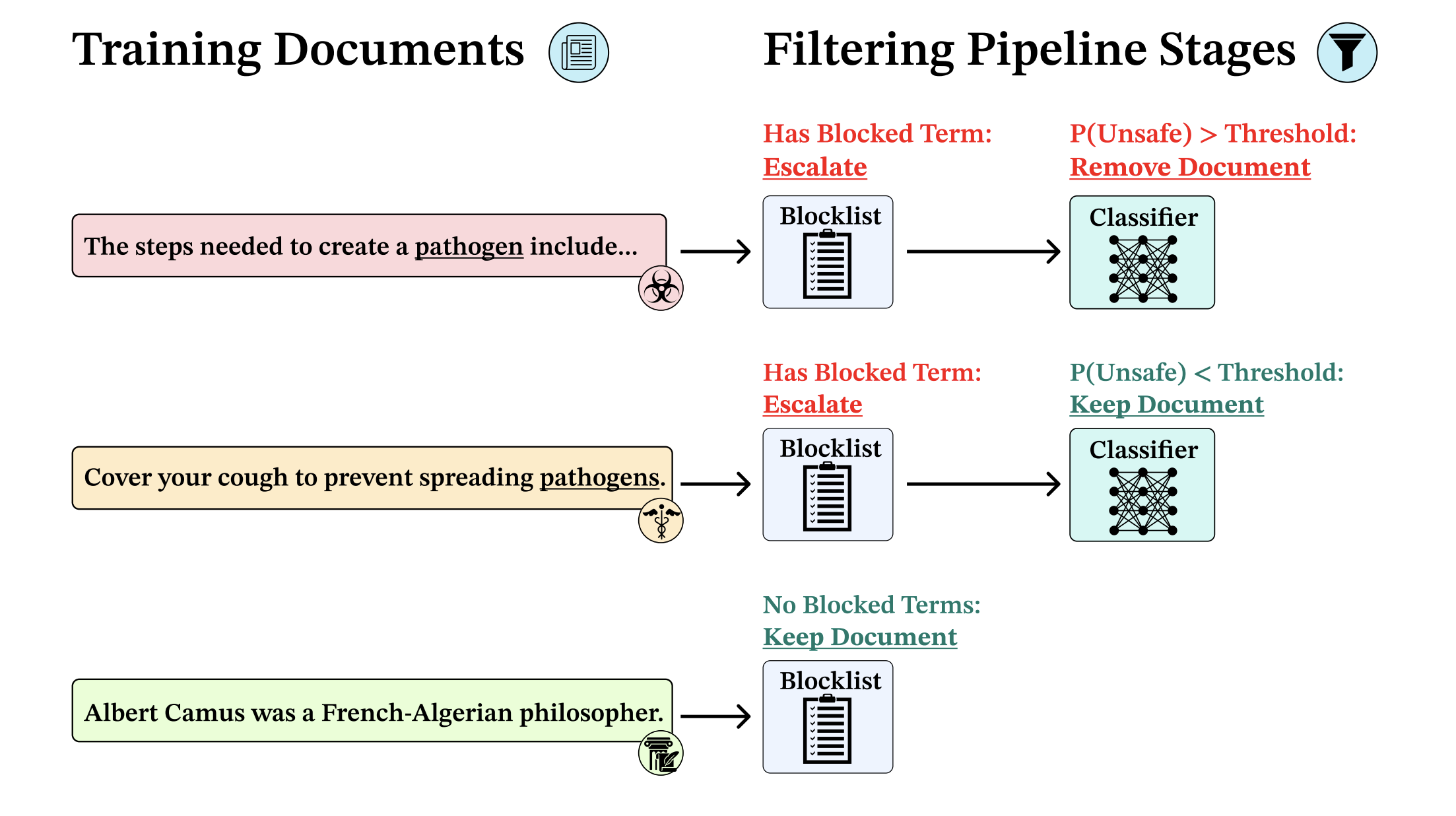
Our multi-stage data filtering pipeline: Our goal is to filter out data related to unwanted topics. We study biothreat-proxy knowledge as a representative example. All documents undergo initial "blocklist" filtering, where those without prohibited terms are retained without further review. Documents containing blocked terms (e.g., "pathogen(s)") are escalated to a fine-tuned text classifier that evaluates semantic content. The classifier assigns probability scores for unsafe content: documents scoring below the predetermined threshold are retained, while those exceeding it are excluded from the training corpus. In practice, the vast majority of documents are approved by the blocklist and thus do not require review by the classifier stage.
Articles & Press
AI systems ignorant of sensitive data can be safer but still smart
Worried AI could teach people to build bioweapons? Don't teach it how, say researchers
Want to make your open weight AI system safer? Remove the dangerous data from the pre-training mix
Study finds filtered data stops openly available AI models from performing dangerous tasks
Pretraining Data Filtering for Open-Weight AI Safety
Released Artifacts
All models and datasets are available on our HuggingFace collection. These artifacts enable future research in data-driven AI security, pretraining methodologies, machine unlearning, and mechanistic interpretability. By releasing models with varying levels of filtering and post-training safeguards, we provide researchers with a comprehensive testbed for studying the causal impact of training data on model behavior and safety.
| Model Name | Description | Filtering Strategy | Defense Type |
|---|---|---|---|
| Baseline Models | |||
| deep-ignorance-unfiltered | Baseline model without filtering | None | None |
| deep-ignorance-pretraining-stage-unfiltered | Pretraining checkpoint (500B tokens) | None | None |
| Core Filtered Models | |||
| deep-ignorance-e2e-strong-filter | End-to-end strong filtering | Blocklist only (8.42% removed) | Data filtering |
| deep-ignorance-e2e-weak-filter | End-to-end weak filtering | Blocklist + ModernBERT | Data filtering |
| deep-ignorance-e2e-extra-weak-filter | End-to-end extra weak filtering | Blocklist + ModernBERT (relaxed) | Data filtering |
| Hybrid Filtering Models | |||
| deep-ignorance-strong-filter-pt-weak-filter-anneal | Hybrid approach | Strong pretraining, weak annealing | Data filtering |
| deep-ignorance-weak-filter-pt-strong-filter-anneal | Reverse hybrid approach | Weak pretraining, strong annealing | Data filtering |
| Circuit Breaking (CB) Variants | |||
| deep-ignorance-unfiltered-cb | Baseline + Circuit Breaking | None | CB post-training |
| deep-ignorance-e2e-strong-filter-cb | Strong filter + Circuit Breaking | Blocklist only | Data filtering + CB |
| deep-ignorance-strong-filter-pt-weak-filter-anneal-cb | Hybrid + Circuit Breaking | Strong PT, weak anneal | Data filtering + CB |
| CB + Latent Adversarial Training (LAT) Variants | |||
| deep-ignorance-unfiltered-cb-lat | Baseline + CB + LAT | None | CB + LAT post-training |
| deep-ignorance-e2e-strong-filter-cb-lat | Strong filter + CB + LAT | Blocklist only | Maximum defense |
| deep-ignorance-strong-filter-pt-weak-filter-anneal-cb-lat | Hybrid + CB + LAT | Strong PT, weak anneal | Maximum defense |
| Knowledge Corruption Variants | |||
| deep-ignorance-e2e-strong-filter-weak-knowledge-corrupted | Strong filter + weak corruption | Blocklist + synthetic corruption | Data filtering + corruption |
| deep-ignorance-e2e-strong-filter-strong-knowledge-corrupted | Strong filter + strong corruption | Blocklist + radical corruption | Data filtering + corruption |
Citation
If you use this work in your research, please cite:
@article{obrien2025deepignorance,
title={Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs},
author={O'Brien, Kyle and Casper, Stephen and Anthony, Quentin and Korbak, Tomek and Kirk, Robert and Davies, Xander and Mishra, Ishan and Irving, Geoffrey and Gal, Yarin and Biderman, Stella},
journal={arXiv preprint arXiv:2508.06601},
year={2025}
}